Actualiteit

Het coronavirus raakt ons allemaal. Het RIVM heeft databronnen gedeeld waar ons datateam een project van heeft gemaakt. In dit eerste artikel nemen we je mee wat we met deze data hebben gedaan en hoe we dit hebben aangepakt. Het doel voor ons datateam was om opgedane Python kennis direct in de praktijk toe te passen. In het tweede artikel zullen we onze resultaten presenteren.
Databronnen van het RIVM
Onlangs heeft het RIVM de website databronnencovid19 gelanceerd. Op deze website staat een overzicht van databronnen en informatiebronnen die gerelateerd zijn aan COVID-19. Van elke bron is een beschrijving en een verwijzing naar de relevante dataset(s) opgenomen. Het RIVM heeft de site opgezet in het kader van de informatievoorziening rondom het coronavirus en COVID-19. Met de nieuwe website faciliteert het RIVM data-analisten, onderzoekers en andere geïnteresseerden om aan de slag te kunnen met data over het coronavirus en COVID-19.
Het projectteam
Bastiaan van den Broek en Job Meijdam hebben de TalentClass gevolgd bij Qquest. Beide hebben zich verder ontwikkeld door een onlinecursus Data Analyst Python te volgen. De kennis die zij opgedaan hebben wilde zij toepassen in een project. Ook Ellen Hoogwater, medior data analist bij Qquest, heeft zich aangesloten bij het project om haar kennis van Python te verbeteren.
De projectopdracht
De opdracht die het team kreeg was het vergelijken van wereldwijde corona data. Het team heeft ervoor gekozen om alle sites die COVID-19 gegevens van de hele wereld rapporteren met elkaar te vergelijken, om vervolgens gevonden verschillen te onderzoeken. Na dit onderzocht te hebben bleken er vier websites te zijn die COVID-19 gegevens wereldwijd rapporteren:
1. European Centre for Disease Prevention and Control
2. Coronavirus Disease Situation Dashboard(WHO)
3. Our World in Data – COVID-19 – Statistics and Research
4. Worldometer
Visualisatie van het proces
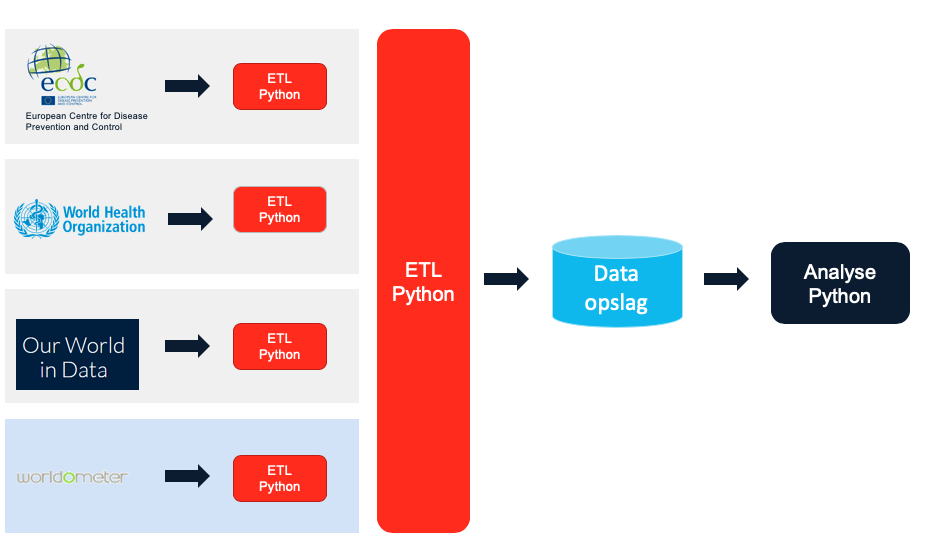
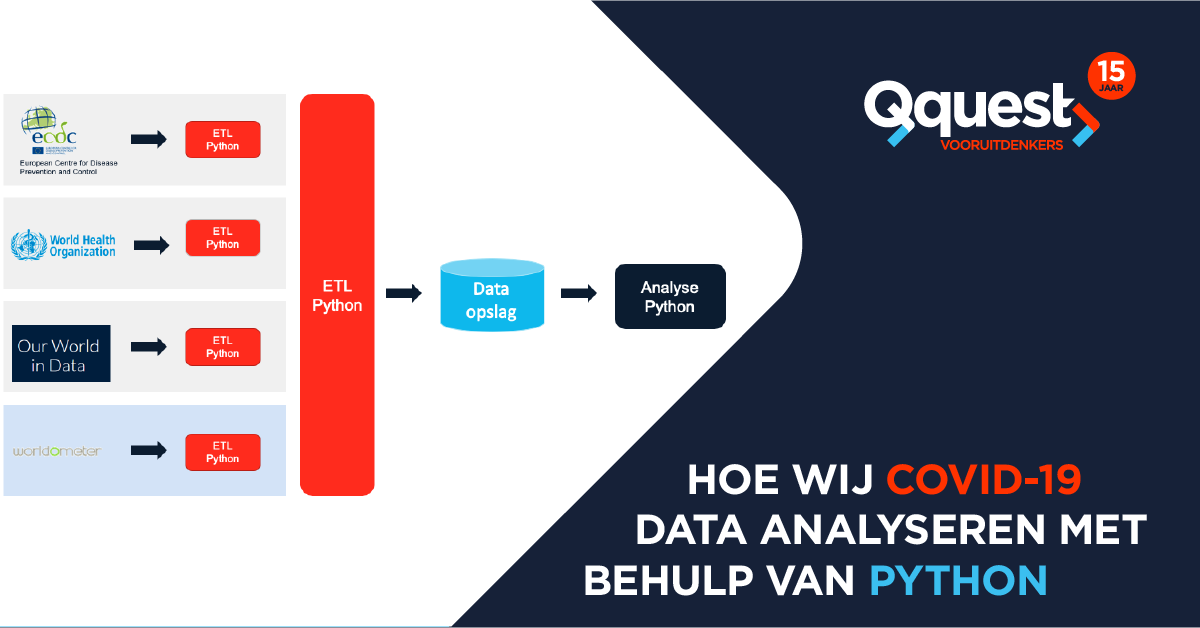
Om het overzichtelijk te maken hebben we een visueel schema gemaakt, zodat je de infrastructuur kunt zien. De vier databronnen staan aan de linkerkant. Iedere databron wordt individueel gescrapet. De eerste drie bronnen bieden de gegevens direct in csv- of Excel-formaat aan. Worldometers biedt haar gegevens aan via de HTML-code. Dit vergt meer tijd en handelingen om deze data in een juist formaat binnen te krijgen.
Binnen het ETL-proces (Extraction, Transformation and Load), hebben we onderstaande punten toegepast op alle data om uiteindelijk vier identieke tussenbestanden te krijgen.
Na de eerste fase van het ETL-proces zijn de gegevens gelijk, waarna ze in de tweede fase aan elkaar gekoppeld worden. Tenslotte staan de gegevens in een database klaar voor analyse. Al deze stappen worden gedaan met behulp van Python.
Agile werkwijze
Het team werkt volgens een Agile aanpak. Taken worden opgepakt, bijvoorbeeld “Haal de gegevens van Worldometer uit de HTML”, en bij gedemonstreerd succes wordt de volgende taak opgepakt, zoals “Haal de gegevens van Worldometer geautomatiseerd van de site”.
Er is afgesproken dat de start van het scrapeproces handmatig zal zijn, waarna de rest geautomatiseerd zal verlopen. De reden hiervoor is dat het coronavirus (hopelijk) van voorbijgaande aard is en dat we de gegevens een beperkt aantal keren moeten verversen.
Voorbereiding tweede artikel
Het team bevindt zich nu in het laatste stadium van het project. Zij zijn nu bezig om de visualisaties in Python te realiseren, waarna de feitelijke analyse kan plaatsvinden. Verwachting is dat het team rond eind mei klaar is. Zodra we deze bevindingen af hebben zullen we deze publiceren.
Het team aan het woord
Op welk vlak had dit project toegevoegde waarde voor jouw persoonlijke ontwikkeling?
Bastiaan van den Broek:
“Voor mij was dit een goede mogelijkheid om mijn Python kennis in de praktijk te gaan brengen. Ook heb ik voor het eerst zelf een scraper op kunnen zetten, waar ik weer veel van heb kunnen leren. Kortom, een interessant en leerzaam project om mee bezig te zijn geweest!”
Job Meijdam:
“Het mooie aan dit project is dat we onze vaardigheden in Python hebben kunnen verbeteren aan de hand van een heel actueel onderwerp. Het is leuk om te zien dat je met nog niet zo veel Python ervaring toch al hele toffe dingen kan maken zoals een scraper. We zijn nu nog druk bezig met het verwerken van alle data en hopelijk levert het straks ook interessante resultaten op!”
Ellen Hoogwater:
“Dit project biedt een hoop leuke uitdagingen. Voor mij persoonlijk was dat vooral mijn ontwikkeling in data-analyse met behulp van Python. Doordat we verschillende databronnen met elkaar willen vergelijken, was het belangrijk om ervoor te zorgen dat we uit elke bron dezelfde informatie halen. Daarvoor moesten we dus onnodige data verwijderen, data opschonen en bijvoorbeeld de datumnotatie gelijktrekken. Nadat we alle data hadden samengevoegd, kon ik aan een andere leuke uitdaging beginnen: het visualiseren van de data in grafieken. Met Python zijn er eindeloos veel mogelijkheden en het is erg leuk om te spelen met de verschillende opties die er zijn om de grafiek zo duidelijk mogelijk te maken. Het doel is tenslotte om de databronnen met elkaar te vergelijken, dus dat moet gelijk uit een grafiek af te lezen zijn. Ik denk dat we in een korte tijd veel hebben geleerd en uiteindelijk met een mooi resultaat kunnen afronden.”
Meer weten over Data & Analytics?
Lees alles over waar wij goed in zijn met Data & Analytics.
Meer weten over Data & Analytics?
Lees alles over waar wij goed in zijn met Data & Analytics.
De laatste ontwikkelingen