Actualiteit

Kennisontwikkeling en het delen van kennis staan centraal bij Qquest. Samen met Actuals werken we in dit kader aan het oplossen van datavraagstukken die spelen bij Actuals. Eén ervan is het kunnen voorspellen van een situatie op basis van veel klantgegevens.

Wie is Actuals?
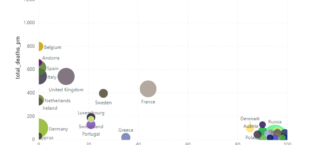
Actuals biedt organisaties die veel transacties verwerken inzicht in de volledigheid en juistheid van hun omzet. Dat doet ze via een SAAS-oplossing. Een klant van Actuals kan hierin het aantal transacties zien en ook welke matchen en welke niet met elkaar matchen. Een transactie bestaat uit data van een bestelling, de vordering, de levering en de betaling. Voor alle data die bij deze ene transactie hoort, bestaan verschillende applicaties binnen en buiten de organisatie. Zo kan de betaling via bijvoorbeeld een provider als Adyen of Mollie lopen. Actuals brengt al deze data uit de verschillende applicaties bij elkaar in de SAAS- oplossing.
Wie is Qquest?
Qquest is een IT-detacheerder die organisaties helpt bij tijdelijke hulp op een project. Dat kan zijn op het gebied van softwaretesten, api-integratie en low-code. Daarnaast biedt Qquest ook een detavast constructie voor bedrijven die op zoek zijn naar vast IT-talent. Door intensieve training en coaching weten we in korte tijd ambitieuze talenten klaar te stomen. Zij starten onder andere in rollen voor data-analyse, beheer, development en business analyse.
Wat is het vraagstuk en hoe is het opgelost?
Normaal gesproken sluit alle transactiedata qua geldstroom op elkaar aan. Maar dat is niet in alle gevallen zo. Bijvoorbeeld omdat de BTW niet betaald is of dat de klant teveel betaalt voor zijn bestelling. En dat kan in de duizenden transacties en euro’s lopen. Een organisatie met 1 miljoen transacties heeft bijvoorbeeld bij 0,2% al 2.000 ‘unmatched transacties’.
De vraag die met elkaar is opgelost luidt: hoeveel unmatched transacties kan een klant van Actuals redelijkerwijs verwachten op basis van de data uit voorgaande maanden? Dat helpt de klant om capaciteit bij de Finance afdeling te plannen en ook om inzicht in trends te krijgen.
Belangrijk hierbij is dat voor het voorspellen rekening moet worden gehouden met werkdagen, weekenden, eenmalige uitschieters, seizoensinvloeden zoals vakanties en andere informatie waardoor niet simpelweg het gemiddelde van de afgelopen periode kan worden genomen.
Hoe hebben we het vraagstuk aangepakt?
Allereerst is met elkaar een beeld gevormd van de data en de bronnen waarin de data staat. Voor een geanonimiseerde testset is sprake van vier bronnen met transactiegegevens. Het is belangrijk eerst de data en hun context te begrijpen, voordat je ermee aan de slag gaat. Alle transacties die bij elkaar horen zijn in één rij in een tabel gezet en er zijn velden toegevoegd aan de tabel, zoals dag, maand en weekendindicatie.
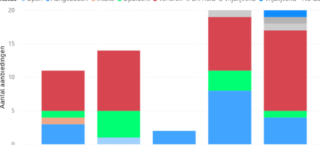
Vervolgens is de tabel opgeschoond en zijn alle rijen zonder match eruit gefilterd. De tabel is, met behulp van Python, geanalyseerd om bepaalde week- en maandtrends, weekend- en seizoensinvloeden te vinden. Uiteindelijk was het resultaat een tabel met het aantal transacties met een bijbehorende datum én analyses per dag, weekend en week, weergegeven in onderstaande grafieken.
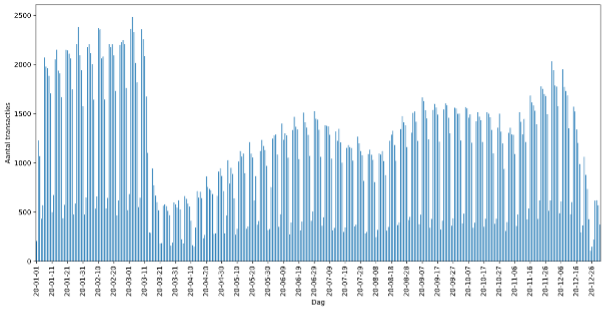
Figuur 1. aantal unmatched transacties in 2020
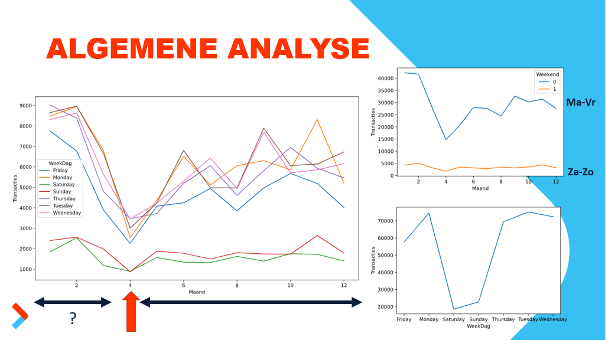
Figuur 2. verdelingen van unmatched transacties
Met Time Series (tijdreeksen) is verdergegaan om een geschikt voorspelmodel te vinden. Bij het analyseren van tijdreeksen zochten we naar structuren en patronen om het onderliggende proces te beschrijven en te verklaren. Maar ook naar manieren om op basis van geschikte modellen toekomstige waarden te voorspellen of om de effecten van alternatieve scenario’s te onderzoeken.
Uiteindelijk is aan de hand van verschillende Time Series modellen gekeken, welke het beste bij het vraagstuk paste. De effectiviteit van de modellen is bepaald aan de hand van een zogenaamd MAPE (Mean Absolute Percentage Error).
Wat is het resultaat geworden?
Er zijn zes modellen getoetst op hun betrouwbaarheid. Hiervan vormt Holt’s Winters Seasonal Exponential Smoothing het model dat het beste presteert met een MAPE van 5%. De voorspelling had een afwijking van 5% op de werkelijke resultaten op een voorspelling van 7 dagen. Hierbij moeten we wel in ogenschouw nemen dat we slechts 8 maanden aan data hebben gebruikt die sterk beïnvloed is door de coronamaatregelen. Niettemin wordt op dit moment het model gebruikt in de praktijk bij Actuals om de betrouwbaarheid te toetsen en klanten al een indruk te geven van dagvoorspellingen.
Inmiddels zijn we gestart met de volgende vraag, namelijk of er in de type unmatched transacties clusters te onderkennen zijn, zodat je gerichter te werk kan gaan met het voorkomen van unmatched transacties. Hierbij kan je denken aan transacties met hetzelfde verschil, of waarbij dezelfde leverancier is betrokken, of waar sprake is van een BTW-issue etc. De stap die we hierbij maken, is dat middels machine learning een systeem zelf clusters kan vinden.
“Als startup zijnde is tijd kostbaar en daarom is het erg fijn om samen met Qquest een oplossing te hebben ontwikkeld die ons veel tijd bespaart bij het monitoren van ons data-landschap. Daarnaast was de samenwerkig erg prettig met een professioneel en pragmatisch Qquest team en we zijn dus erg blij met het fraaie machine learning algoritme als resultaat”
Peter Lem – Actuals.io
Valkuilen waar we mee te maken kregen
Vraagstukken over voorspellen zijn vaak uniek waarbij je onderweg tegen allerlei uitdagingen en problemen aanloopt. Zo ook bij dit vraagstuk.
Nieuwsgierig geworden?
Ben je naar aanleiding van deze case nieuwsgierig geworden wat wij voor jou kunnen betekenen of heb je vragen over de case? Neem dan gerust contact met ons op. We gaan graag met je in gesprek onder het genot van een goede kop koffie.
Meer weten over Data & Analytics?
Lees alles over waar wij goed in zijn met Data & Analytics.
Meer weten over Data & Analytics?
Lees alles over waar wij goed in zijn met Data & Analytics.
De laatste ontwikkelingen